|
|
|
|
|
|
|
Trouver un fil conducteur dans le labyrinthe des
méthodes et des tests statistiques |
|
afin de traiter les données expérimentales de
manière rigoureuse |
|
et d’en garantir la qualité |
|
|
|
|
Statistique |
|
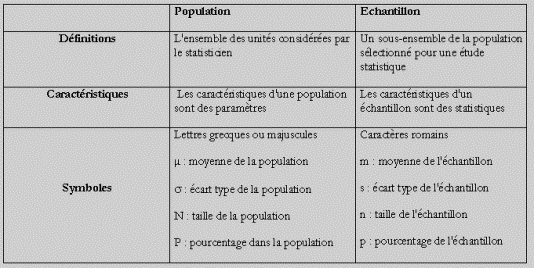
Population – Echantillon |
|
Nature des données |
|
|
|
|
|
|
|
Il vient du terme latin |
|
status : état ou |
|
statisticus : qui a trait à l’état |
|
Le terme statistique apparaît la 1ère fois en
1589 |
|
Son application est plus ancienne et remonte à
3000 ans avant J.C. |
|
|
|
|
L’ensemble des méthodes permettant de traiter
des données et d’analyser leurs variations. |
|
Ses méthodes relèvent principalement du domaine
des mathématiques. |
|
L’outil informatique et graphique a permis
d’alléger la tâche ardue du calcul mathématique . |
|
Il a permis de se focaliser sur le problème statistique lui-même |
|
|
|
|
Les statistiques désignent les données
numériques systématiquement établies sur un sujet donné. |
|
Toute donnée ne peut être considérée comme
statistique |
|
Pour ce faire, elles doivent répondre à certains
critères. |
|
|
|
|
|
|
Ensemble des éléments d’un champ d’analyse ayant
des propriétés communes et pris en considération par un statisticien pour
être quantifié. |
|
Les éléments sont appelés unités : des animaux,
des malades, des tumeurs, des cellules, des mesures,... . |
|
Elle peut être dénombrable : les morts, les
patients,.. |
|
Elle peut être indénombrable : le nombre
d’expériences. |
|
|
|
|
Travailler sur toute la population est coûteux
ou impossible |
|
Un échantillon est une partie représentative de
la population. |
|
|
|
|
|
Pour le laboratoire : |
|
Objet individualisé, expédié pour analyse. |
|
Attribution d’un numéro d’ordre qui le suit
partout. |
|
Pour un agent de contrôle : |
|
Ensemble de prélèvements sur un même lot. |
|
Sur ces échantillons, plusieurs mesures sont
effectuées : répétitions. |
|
|
|
|
|
|
|
|
|
Valeurs observées pour les variables. |
|
Représentées par les lettres de la fin de
l’alphabet suivi d’un indice i (xi,yi,zi) |
|
L’indice i permet de différencier les
observations, i variant de 1 à n. |
|
Représentation : |
|
Variable qualitative : un symbole. |
|
Variable quantitative : une valeur. |
|
Indépendance : dépend de l’expérimentateur. |
|
|
|
|
Elles ont un sens plus large que les
observations: |
|
elles
représentent aussi les transformations se référant aux observations? |
|
|
|
|
Chaque individu d’une même population varie
selon un critère appelé variable ou caractère. |
|
Elle peut être qualitative ou quantitative. |
|
Représenté par une lettre de la fin de
l’alphabet : x, y ou z. |
|
La lettre majuscule représente la population (X) et la minuscule l’échantillon
(x) |
|
|
|
|
|
|
Elle comporte un libellé : description de la
variable |
|
Elle comporte des modalités : les différents
niveaux que peut prendre la variable |
|
|
|
|
|
|
Modalités sont non numériques et représentent
des catégories. |
|
Dichotomique : elle ne comporte que 2 modalités. |
|
Textuelle : les modalités sont du texte. |
|
|
|
|
Variable dont les modalités ont des valeurs numériques
: nombre de ml d’un titrage, la température, le temps, .. |
|
Lorsque les modalités sont nombreuses, elles
peuvent être regroupées. Ce regroupement transforme la variable continue en
discrète. |
|
|
|
|
|
|
Echelle nominale : échelle de variables
qualitatives dont les modalités ne sont pas naturellement ordonnées :
homme-femme, pile-face, mort-vivant,.. |
|
Echelle ordinale : les modalités peuvent être
ordonnées : qualité de la vie : détérioration, statu-quo, amélioration. |
|
|
|
|
Echelle de rapport : échelle de mesure de
données quantitatives qui permet les additions (échelle de température en
°C). Sur ce type d’échelle, le zéro ne représente pas l’absence de la
variable mais est représenté arbitrairement. |
|
Echelle d’intervalle : le zéro représente
l’absence de la variable : le poids, la température en °K. |
|
|
|
|
Variable indépendante ou explicative (V.I.):
variable dont on recherche l’influence ou l’effet. |
|
Variable dépendante ou expliquée (V.D.) :
variable dont on cherche à comprendre ou à prévoir le comportement. |
|
|
|
|
|
La relation entre 2 V.D. : corrélation. |
|
Corrélation linéaire simple : 2 variables
quantitatives, continues et distribuées normalement |
|
Association : les 2 variables sont qualitatives. |
|
Corrélation de point : les 2 variables sont
binaires |
|
La relation entre la V.D. et V.I. : la
régression |
|
Régression simple : 1 V.D. et 1 V.I. |
|
Régression multiple : 1 V.D. et plusieurs V.I. |
|
Corrélation canonique : Plusieurs V.D. et
plusieurs V.I. |
|
|
|
|
|
|
Variable contrôlée : l’expérimentateur peut
obtenir pour cette variable la modalité désirée : la fixation du temps dans
l’étude cinétique. |
|
Variable aléatoire : variable soumise à des
fluctuations non contrôlée suite à des micro-fluctuations d’un grand nombre
de facteurs. |
|
|
|
|
|
L’analyste lorsqu’il répète ses mesures obtient
des valeurs différentes. |
|
A priori, il ne peut connaître le résultat car
il est en partie soumis au hasard (alea en latin) . |
|
Comme l’échantillon est homogène, on scindera le
résultat en 2 parties : |
|
Une partie fixe : la vateur recherchée ou
paramètre de position. |
|
Une partie variable : le paramètre de
dispersion. |
|
|
|
|
|
|
|
|
Les fluctuations aléatoires ont des conséquences
lorsque l'on compare deux groupes |
|
Ces fluctuations peuvent faire apparaître des
différences entre les groupes induites uniquement du fait du hasard |
|
|
|
|
|
|
|
|
Paramètre associé à une mesure ou un résultat
pour caractériser une dispersion associée à la quantité mesurée (measurand). |
|
Cette incertitude sera souvent caractérisée par
l’intervalle de confiance. |
|
On préférera ce terme à celui de précision mal
adapté. |
|
|
|
|
Erreur d’échantillonnage : échantillon non
représentatif |
|
Biais de l’instrument de mesure |
|
Limites de l’instrument de mesure |
|
Pureté du réactif, du matériel de référence |
|
Variations des conditions expérimentales (pH,
température) |
|
Traitement de l’échantillon (récupération après
extraction, contamination) |
|
Erreurs de calculs (modèle de calibration
inapproprié). |
|
Erreur aléatoire : origine non définie |
|
|
|
|
L’erreur est définie comme la différence entre
le résultat individuel et la vraie valeur. C’est un concept idéalisé car le
plus souvent, on ne connaît pas la vraie valeur. |
|
L’incertitude a la forme d’une étendue et est
applicable à toutes les déterminations. |
|
Par chance, un résultat peut être très proche de
la réalité (peu d’erreur) mais il peut avoir une grande incertitude
(étendue de variation élevée) |
|
|
|
|
Erreurs aléatoires : dues à des variations
imprévisibles |
|
Erreurs systématiques : erreur constante et donc
prévisible due à l’appareillage, l’échantillon, le réactif, les
satndards,.. |
|
Erreurs grossières ou interdites : erreurs le
plus souvent dues à l’expérimentateur. |
|
|
|
|
Toute mesure a une incertitude |
|
L’incertitude est un paramètre qui caractérise
l’étendue des valeurs à l’intérieur de laquelle la valeur vraie est
supposée se trouver |
|
Un résultat doit être exprimé avec son
intervalle de confiance. |
|
|
|
|
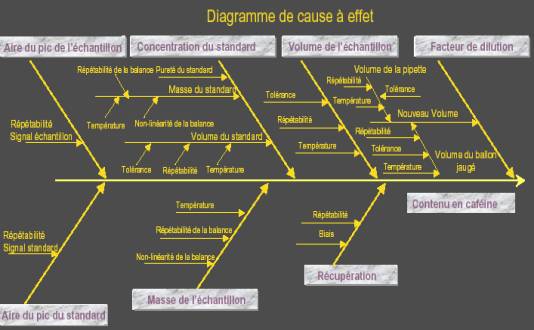
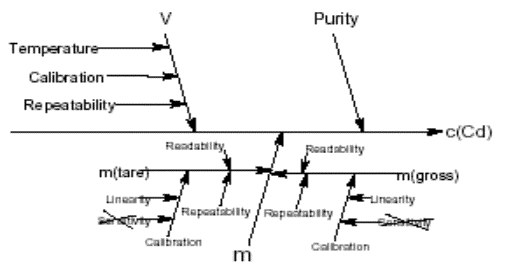
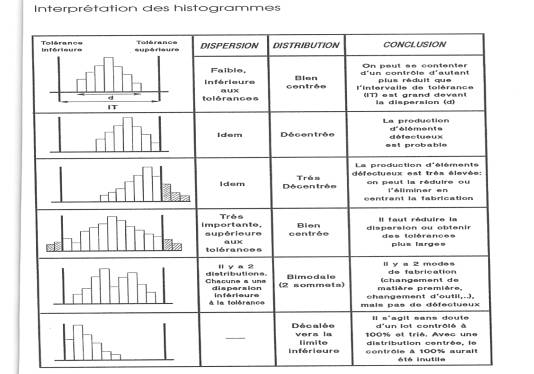
Ecrire la procédure complète pour l’obtention du
résultat et déterminer les paramètres qui interverviennent dans le
processus |
|
Etudier la méthode pour identifier les facteurs
qui interviennent dans le résultat |
|
Construction d’un diagramme (Ichikawa) |
|
|
|
|
|
|
|
|
|
|
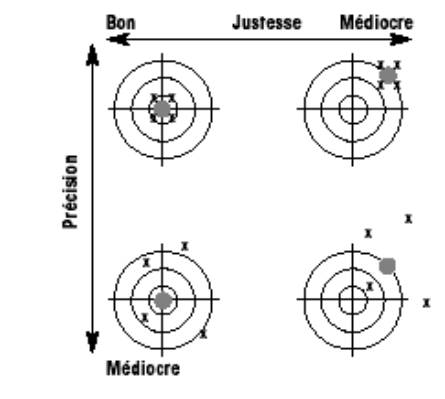
Définition ICH : étroitesse de l’accord d’une
série de mesures obenues à partir d’un échantillon homogène. |
|
Statistique : exprimée par la variance,
l’écart-type ou le coefficient de variation. |
|
La précision est indépendante de la valeur
vraie. |
|
|
|
|
|
Désignation qualitative pour l’étroitesse de
l’accord entre les résultats de mesures consécutives de la même substance,
réalisées dans les mêmes conditions de mesure : |
|
même
procédure d’analyse |
|
même
observateur |
|
objets
identiques (même échantillon, même matériau) |
|
en
l’espace de brefs intervalles de temps |
|
même
instrument de mesure |
|
même
lieu |
|
|
|
|
|
|
|
|
|
Désignation qualitative pour l’étroitesse de
l’accord mutuel entre les résultats de mesures de la même substance,
réalisées dans des conditions de mesure différentes qui peuvent concerner : |
|
Le
principe ou la méthode de mesure |
|
L’observateur |
|
L’appareil de mesure |
|
L’étalon
secondaire |
|
Le lieu |
|
Les
conditions d’utilisation |
|
L’heure |
|
|
|
|
Etendue de l’écart par rapport à la valeur
vraie. |
|
|
|
|
|
|
|
|
|
|
Objectif principal : |
|
Décrire les données sous une forme
compréhensible et utilisable. |
|
Classer les données, les organiser et les
présenter clairement sous forme de : |
|
tableaux, |
|
présentations graphiques |
|
résumés numériques. |
|
Synonymes
: analyse des données et statistique exploratoire. |
|
|
|
|
|
|
|
|
A- Présentation sous forme de tableaux |
|
|
|
|
|
|
|
|
B- Présentation graphique |
|
|
|
|
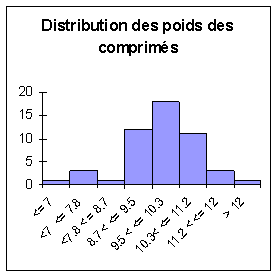
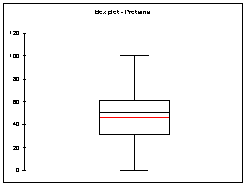
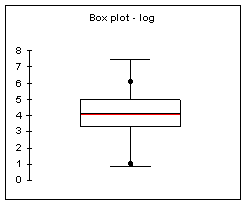
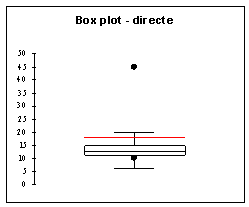
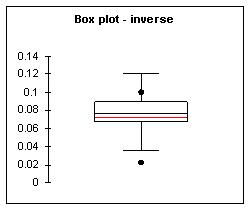
Domaine d’application : grandes séries de
données continues : >50 |
|
Objectif : déterminer la forme de la dispersion
ou détecter des valeurs aberrantes. |
|
|
|
|
|
|
|
|
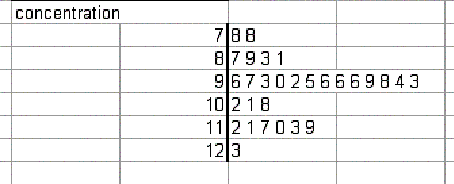
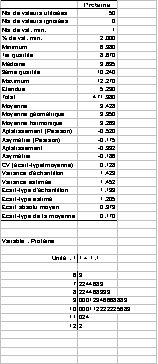
Développé par Tukey dans les années 60 |
|
Le graphique garde les valeurs des données et ne
les transforme pas en fréquence. |
|
Les tiges (Stems) correspondent aux nombre de
chiffres significatifsau début de chaque donnée |
|
Les feuilles (leaves) correspondent aux chiffres
suivants. Il y en a une par observation. |
|
Applicable aux séries de mesures continues de
taille moyenne (n<100) |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
C- Détermination des paramètres statistiques |
|
|
|
|
|
|
Moyenne : |
|
|
|
|
|
|
|
Données groupées : |
|
|
|
|
Données quantitatives continues. |
|
Distribution normale |
|
Absence de valeurs aberrantes |
|
Echantillonnage indépendant |
|
|
|
|
La somme algébrique des écarts entre observés la
moyenne arithmétique est nulle. |
|
Elle minimise la somme des carrés des écarts à
elle-même. |
|
La moyenne est considérée comme le centre de
gravité d’une distribution. |
|
Estimateur (µ) de la moyenne de la population. |
|
On peut modifier le poids des données par
l’utilisation de moyennes pondérées |
|
|
|
|
|
|
Universellement répandue et acceptée |
|
Se prête
aux calculs algébriques et est programmée sur toutes les calculettes
et tableurs. |
|
Répond au principe des moindres carrés et
confère ainsi à la moyenne la plus petite erreur. |
|
Meilleur estimateur de la moyenne de la
population :m est le meilleur estimateur de µ. |
|
|
|
|
|
|
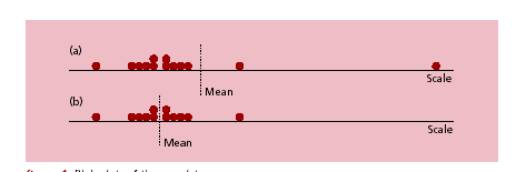
Fortement influencée et donc peu robuste en
présence de données extrêmes. |
|
Peu représentative d’une population hétérogène
(distribution polymodale). |
|
Non représentative de la tendance centrale en
cas d ’asymétrie. |
|
Non représentative de la tendance centrale en
présence de nombreuses données en-dessous du seuil de détection. |
|
|
|
|
|
|
|
|
|
|
|
|
Mesure de la tendance centrale définie comme la
valeur qui partage la distribution d’une série d’observations triées en
ordre croissant ou décroissant en deux parties égales |
|
S’applique aux données quantitatives continues
ou ordinales |
|
|
|
|
|
Tri des données puis: |
|
Nombre impair : la médiane est la (n+1)/2 donnée |
|
Nombre pair : moyenne entre n/2 et la suivante |
|
|
|
|
|
Avantages |
|
Plus robuste : moins influencée par les données
extrêmes |
|
Inconvénients |
|
Se prête mal aux calculs |
|
N’est pas présente sue les calculettes |
|
Suppose l’équi-partition des données |
|
|
|
|
|
|
Valeur la plus fréquemment rencontrée |
|
|
|
|
N’est pas affecté par les données extrêmes |
|
Peut être calculé sur des valeurs nominales. |
|
Bon indicateur de populations hétérogènes
(multi-nodales). |
|
Le mode est un score réellement observé alors
que la médiane ou la moyenne peuvent correspondre à des valeurs non
observées. |
|
|
|
|
|
|
Se prête mal aux calcul statistiques et
algébriques. |
|
N’est pas programmé sur calculettes. |
|
Ne tient compte que des éléments qui se
rapprochent de la ou des classes modales. |
|
Pour les données continues, son calcul varie
selon le choix de l’intervalle de classe. |
|
N’est un bon indicateur de la tendance centrale
que s’il y a une valeur dominante. |
|
|
|
|
|
|
|
|
|
|
Extension du concept de médiane |
|
Le quartile divise l’ensemble des données en 4
parties |
|
Le décile divise l’ensemble des données en 10
parties |
|
Le centile divise l’ensemble des données en 100
parties |
|
|
|
|
Variable quantitative continue |
|
Application pour tout type de distribution |
|
Les déciles et centiles requièrent un grand
nombre d’observations |
|
|
|
|
|
|
Différence entre la valeur la plus élevée et la
plus faible. |
|
Dépend des données extrêmes. |
|
|
|
|
|
|
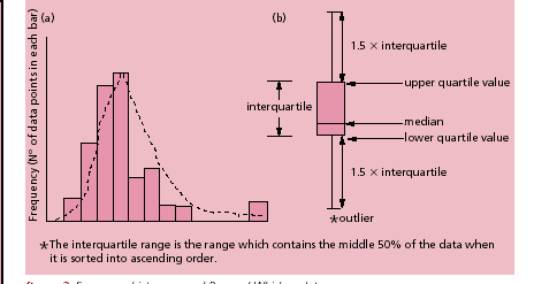
Intervalle comprenant 50% des observations les
plus au centre de la distribution. |
|
Evite la dépendance aux données extrêmes. |
|
Joue un rôle central dans la construction du
Box-plot. |
|
Tronque une top grande partie des données. |
|
|
|
|
|
|
Variance population : |
|
|
|
Variance échantillon |
|
|
|
|
|
|
3. L’écart type
(standard deviation) |
|
|
|
|
Ecart-type de la population |
|
|
|
|
|
Ecart-type de l’échantillon |
|
|
|
|
|
|
|
|
Variable aléatoire |
|
Variable quantitative continue |
|
Distribution normale |
|
|
|
|
4. Autres mesures de dispersion. |
|
|
|
|
|
Expression mathématique : |
|
|
|
Avantage : |
|
Indépendant du choix des unités |
|
Permet de comparer des distributions exprimées
en unités différentes. |
|
Désavantage :
est inefficace quant la moyenne
tend vers 0. |
|
|
|
|
Expression mathématique : |
|
|
|
|
|
|
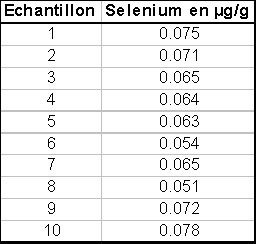
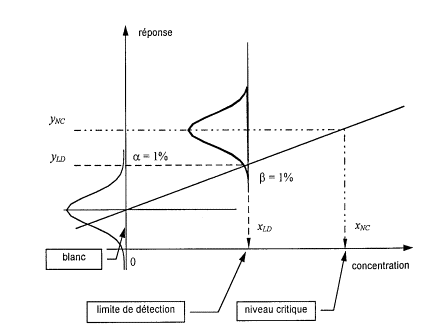
La limite de détection est définie
conventionnellement comme égale à 3 fois l’écart-type de lma moyenne des
essais à blanc (n>20) |
|
C’est une valeur corrigée du blanc en-dessous de
laquelle on ne peut affirmer que la valeur vraie n’est pas nulle. |
|
|
|
|
Calculée comme 6s sur 60 mesures de blancs de
préparation. |
|
|
|
|
|
|
1. Le coefficient d’asymétrie
(Skewness) |
|
|
|
|
Si le coefficient est nul, la distribution est
symétrique. |
|
Si le coefficient est négatif, la distribution
est asymétrique à droite |
|
Si le coefficient est positif, la distribution
est asymétrique à gauche |
|
|
|
|
|
|
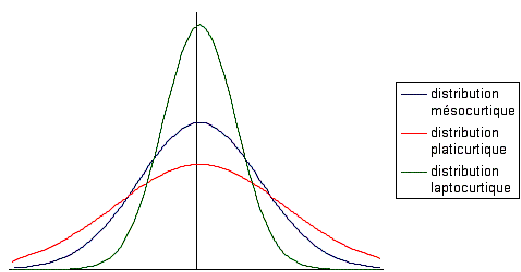
2. Le coefficient d’aplatissement (Kurtosis) |
|
|
|
|
|
|
Indicateur de la concentration des données
autour du mode |
|
|
|
|
|
|
|
|
A- Présentation sous forme de tableaux |
|
|
|
|
|
|
|
|
|
|
B- Présentation graphique |
|
|
|
|
|
|
|
|
Couple de données quantitatives - qualitatives |
|
Comparaison de plusieurs groupes. |
|
|
|
|
|
|
|
|
Couple de données quantitatives - quantitatives |
|
Détecter la présence d ’une relation
éventuelle |
|
|
|
|
C- Détermination des paramètres |
|
|
|
|
|
Régression : relation entre 2 v. continues : |
|
L’une a un caractère aléatoire et est appelée dépendante
ou expliquée |
|
L’autre est une v. indépendante et contrôlée.
Elle est aussi qualifiée d’explicative pour marquer la relation de cause à
effet. |
|
Corrélation : concordance entre les valeurs
numériques de 2 v. continues dépendantes. Pas de relation de cause à effet. |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
I. Notions de distribution |
|
|
|
|
|
|
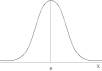
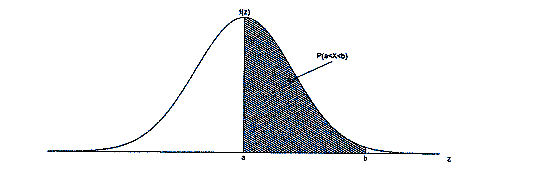
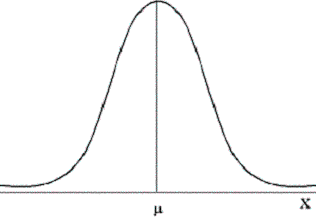
La fonction de densité permet de déterminer la
probabilité qu’une variable aléatoire continue prenne une valeur dans un
intervalle fixé |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Test de K.S. >50 |
|
Test de Shapiro <50 |
|
|
|
|
|
|
Représentativité |
|
Normalité de la distribution |
|
Homogénéité de la variance |
|
Additivité des effets |
|
|
|
|
|
|
|
|
Ecart-type est proportionnelle à la moyenne |
|
Distribution est log-normale (fréquent en
biologie) |
|
|
|
|
|
|
|
|
Souvent utilisée pour les batteries de test
utilisant le temps comme variable mesurée |
|
|
|
|
Fréquemment utilisée pour une distribution de
Poisson |
|
|
|
|
|
|
Transformation en z : Z = (x-µ)/s.
si z > 3 valeur suspecte |
|
Transformation en u (z modifiée) :
si
u>3.5 valeur suspecte |
|
MAD
la médiane des valeurs absoluesí xi -`xý. |
|
|
|
|
|
|
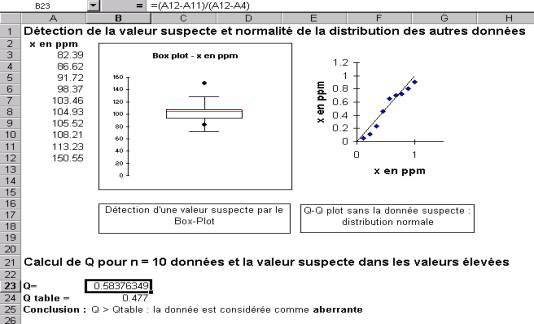
1. Test de la valeur extrême ou
test de Dixon |
|
|
|
|
Nombre de mesures : ≤8 |
|
Risque a utilisé : 1% |
|
Type de distribution : la distribution des
autres données est supposée être normale. |
|
Nombre de données aberrantes : 1 |
|
|
|
|
|
|
|
|
2. Test de discordance ou
test de Grubbs |
|
|
|
|
Nombre
de mesures : entre 8 et 50 |
|
Risque a utilisé : 1% |
|
Type de distribution : la distribution des
autres données est supposée être normale. |
|
Nombre de données aberrantes : 1 (test
simple) ou 2 (test double) |
|
|
|
|
|
|
|
|
Calcul de la somme des carrés des écarts par
rapport à la moyenne : SCE |
|
Calcul de la moyenne sans les 2 données
suspectes |
|
Calcul de la somme des carrés des écarts par
rapport à la moyenne après élimination : SCEss |
|
Calcul du rapport : Q = SCE/SCEss |
|
Si Q < Q table : données aberrantes |
|
|
|
|
II. Notions sur les tests d’hypothèses |
|
|
|
|
Condition présumée vraie en absence de fortes
évidences du contraire. |
|
Ne pas mettre comme hypothèse nulle, l’hypothèse
que vous voulez vérifier. |
|
Si l’hypothèse nulle est rejetée, alors
l’hypothèse de recherche, appelée pour cette raison hypothèse alternative peut être
envisagée |
|
|
|
|
|
|
|
|
La technique du test d’hypothèse a été mis au
point par Fisher en 1951. |
|
Il s’est basé sur un^problème très
« anglais » : le goût du thé est-il influencé par l’ordre des
ingrédients : le thé et le lait. |
|
|
|
|
|
|
|
|
L’hypothèse alternative ou hypothèse de
recherche est représentée par H1 ou Ha |
|
Elle peut prendre une forme unilatéral :
- médicament > placebo q1
> q0. |
|
inhibiteur < contrôle : q1 < q0. |
|
Test bilatéral : |
|
- test <> contrôle : q1 <> q0. |
|
|
|
|
|
|
III. Notions sur les risques statistiques |
|
|
|
|
L’hypothèse nulle doit être formulée de telle
façon que son rejet erroné constitue une erreur plus grave que son
acceptation erronée. |
|
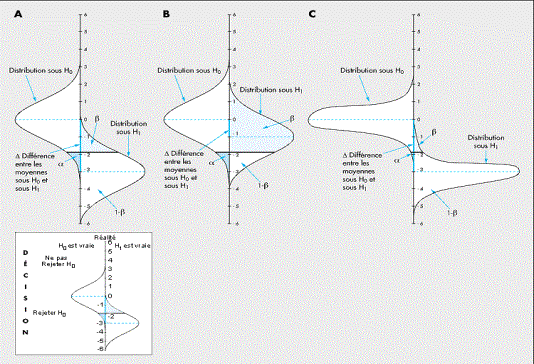
Les notions de risque d ’erreur de type I (a)
et de type II (b) en découle. |
|
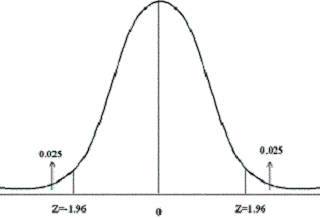
Les valeurs les plus courantes : 0.05 et 0.01 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Risque a |
|
C’est le risque de croire que le procédé n’est
pas correctement réglé alors qu’il l’est. |
|
|
|
C ’est croire que le médicament est
efficace alors que c’est un Placebo. |
|
Risque b |
|
C’est le risque de croire que le procédé est
correctement réglé alors qu’il ne l’est pas. |
|
|
|
C ’est ne pas mettre sur le marché un
médicament croyant que c ’est un Placebo alors qu ’il est
efficace |
|
|
|
|
|
|
|
|
I. Etude Pilote : nombre de mesures nécessaires |
|
|
|
|
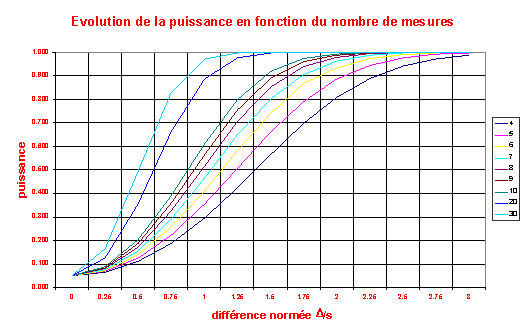
Le but d ’une étude pilote est souvent
d ’évaluer la puissance du test : ai-je une puissance suffisante pour
voir une différence ? |
|
Cette puissance dépend de 2 facteurs : la
variabilité des mesures et le nombre de mesures. |
|
|
|
|
|
|
II. Intervalle de confiance |
|
|
|
|
|
Intervalle de confiance I.C. |
|
si n >30 : |
|
|
|
Intervalle de confiance |
|
I.C. si n ≤30 : |
|
|
|
|
|
|
III. Comparaison d’une moyenne avec une
référence |
|
|
|
|
|
Sélectionner les tests d ’hypothèses |
|
Comparer l ’échantillon à une valeur fixée |
|
Comparer 2 populations |
|
Identifier les hypothèses soutenant les tests
statistiques |
|
Forme de distribution, dispersion, indépendance. |
|
Robustesse |
|
|
|
|
H0 : µ=C vs µ#C |
|
H0 : µ£C vs µ>C |
|
H0 : µ³C vs µ<C |
|
|
|
|
|
|
Indépendance des échantillons |
|
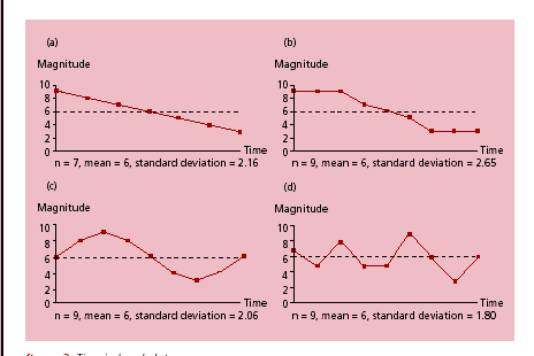
Moyenne distribuée normalement : sensibilité aux
« outliers » |
|
Théorème central limite : pour de grands
échantillons, la distribution tend à être normale. |
|
|
|
|
|
|
Pour de faibles échantillons, les tests de
normalité sont conseillés |
|
De légères transgressions n ’invalident pas
le test t pour de grands échantillons. |
|
|
|
|
|
|
Difficultés en présence de valeurs en-dessous de
la limite de détection contrairement aux tests sur les rangs et les
proportions. |
|
La moyenne et l ’écart-type sont influencés
par les « outliers ». |
|
|
|
|
Le test t n’est pas robuste face aux
« outliers » |
|
Le test du rang signé de Wilcoxon est plus
robuste |
|
Le test de Wilcoxon est moins puissant : il a
moins tendance à rejeter l’hypothèse nulle quand elle est fausse que le
test t |
|
|
|
|
|
|
Etape 1- Calcul de la moyenne m et
l ’écart-type s et l’écart-type sur la moyenne sm. |
|
Etape 2- Estimer la valeur critique de t1-a
dans les tables pour le risque a et n mesures. |
|
Etape 3-Calcul du tobs = |m-C| / sm. |
|
|
|
|
|
|
|
Etape 4- comparer t et t(1-a) : |
|
si t³ t1-a : H0
est rejetée : suite étape 6 |
|
si t< t1-a : pas d ’évidence pour rejeter
l ’hypothèse nulle. |
|
|
|
|
|
Etape 5 : les résultats du test peuvent être : |
|
l ’hypothèse nulle est rejetée et il semble
que la vraie moyenne est plus grande (plus petite) que C. |
|
L ’hypothèse nulle n’est pas rejetée et le
test des faux négatifs n’est pas vérifié. C paraît plus grand (ou plus
petit) que m : l ’échantillon est trop petit. |
|
|
|
|
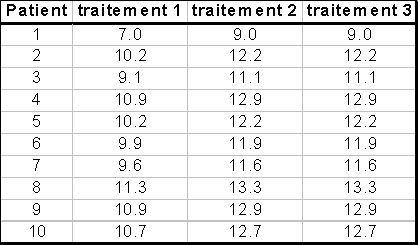
III. Comparaison de 2 populations |
|
|
|
|
2 moyennes µ1 et µ2 |
|
Cas 1 : µ1 - µ2£d0 vs
µ1 - µ2 > d0 |
|
Cas 2 : µ1 - µ2 ³ d0 vs
µ1 - µ2< d0 |
|
|
|
|
|
|
Indépendance des 2 séries d ’échantillons |
|
Moyennes distribuées normalement : ! sensibilité
aux « outliers » |
|
Théorème central limite : pour de grands
échantillons, la distribution tend à être normale. |
|
|
|
|
|
|
Robuste par rapport à la normalité de la
distribution et à l ’égalité des variances, |
|
En cas de non égalité des variances, appliquer
la correction de Satterthwaite |
|
Des tests non-paramétriques peuvent être
appliqués en cas de rejet. |
|
Pas robuste vis à vis des outliers |
|
|
|
|
|
|
|
Les données sont-elles indépendantes les unes
des autres ? |
|
Oui : données non appariées (ou non pairées) |
|
Non : les données sont pairées. |
|
Dans ce cas, les données sont indépendantes. |
|
Les données sont-elles distribuées normalement ? |
|
Oui : test t |
|
Non : test de Wilcoxon-Mann-Whitney |
|
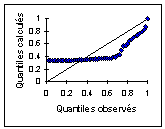
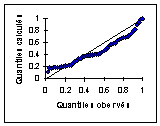
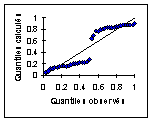
On le vérifie par un Q-Q plot |
|
|
|
|
|
|
|
La distribution est normale, questions
supplémentaires |
|
Les variances sont-elles semblables ? |
|
Oui : les d.d.l. = n1 + n2
– 2 |
|
Non : correction et diminution des d.d.l. |
|
Y a-t-il des données suspectes (Q-Q plot) ? |
|
Oui :
test adapté (Dixon, Grubbs,..) |
|
Si le test est positif, éliminer la donnée et
refaire le test de comparaison sans la donnée |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
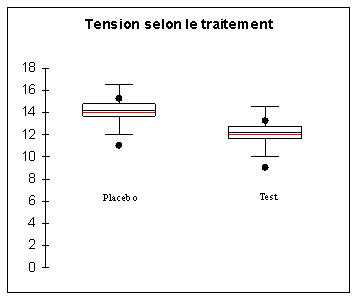
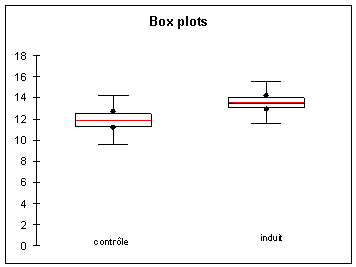
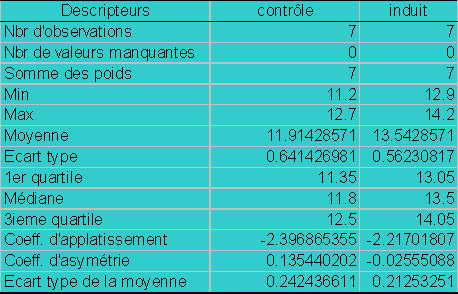
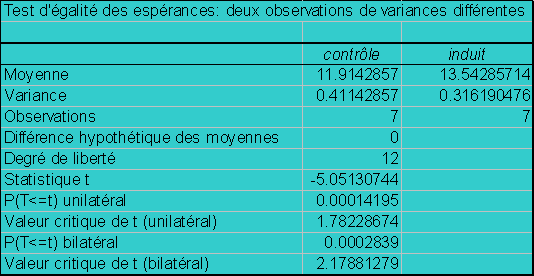
Hypothèse nulle H0 : mcontrôle
= minduit |
|
|
|
Hypothèse alternative H1 : minduit
> mcontrôle |
|
|
|
|
|
|
|
Rejet de l’hypothèse nulle : |
|
tobs > ttables |
|
p <0.05 |
|
|
|
|
I. Analyse de variance ANOVA |
|
|
|
|
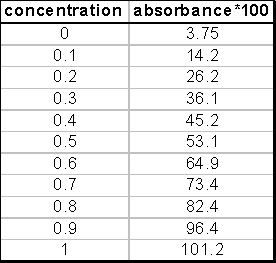
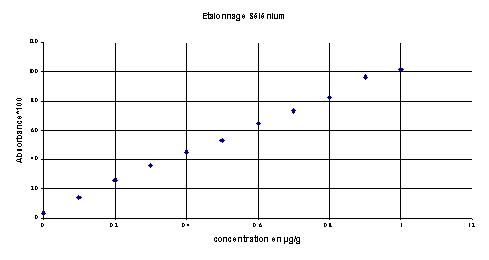
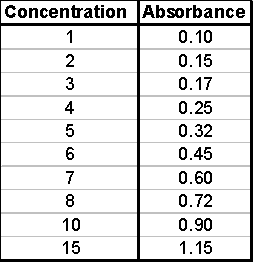
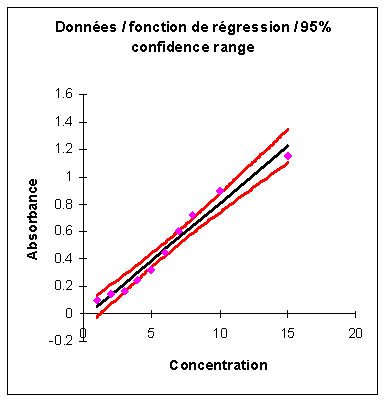
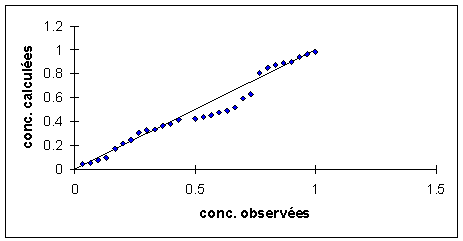
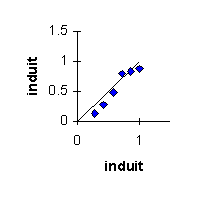
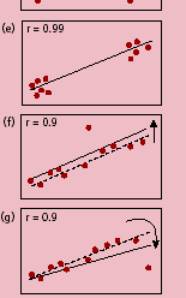
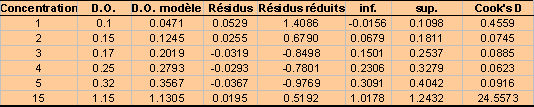
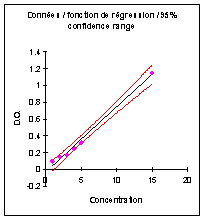
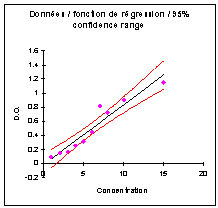
II. Analyse de régression : la droite de
calibration |
|
|
|
|
|
|
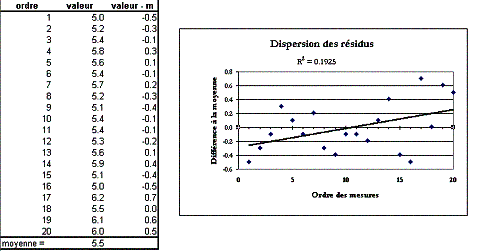
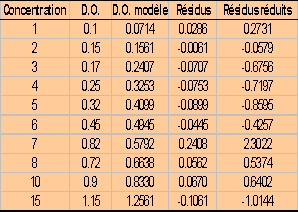
Pour chaque point, on calcule la pente a1
et l’ordonnée à l’origine a0sans ce point. |
|
La distance de Cook calcule la somme des
variations avec et sans le point sur les 2 paramètres : |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Limite de Détection = 3*sa0/a1 |
|
|
|
Niveau critique = 6*sa0/a1 |
|
|
|
Limite de Quantification = 10*sa0/a1 |
|
|
|
|
|
|
Guidance for Data Quality Assessment, Practical Methods for Data Analysis EPA QA/G-9, July 2000 |
|
The Fitness for Purpose of Analytical Methods,
EURACHEM Guide, Decembre 1998. |
|
Quantifying Uncertainty in Analytical
Measurement, EURACHEM/CITAC Guide, 2000 |
|

 Commentaires
Commentaires{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
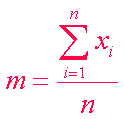{kind=link}
{kind=link}
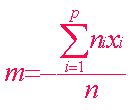{kind=link}
{kind=link}
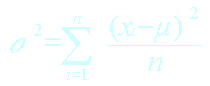{kind=link}
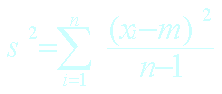{kind=link}
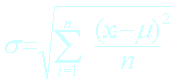{kind=link}
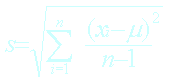{kind=link}
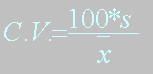{kind=link}
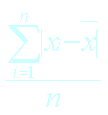{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
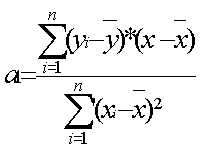{kind=link}
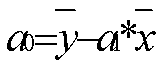{kind=link}
{kind=link}
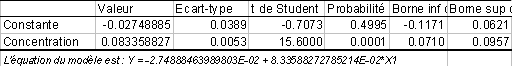{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
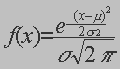{kind=link}
{kind=link}
{kind=link}
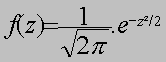{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
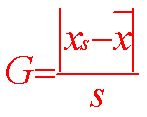{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
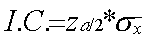{kind=link}
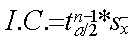{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
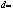{kind=link}
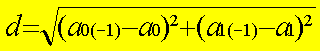{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}